Benchmarking component allocation strategies in an ECS
Preface: Consider all of the code in this article to be psuedocode. It is not guaranteed to compile as-is.
In the last article I discussed a number of storage strategies for components in an entity component system. In this article, I will first describe the public interface for a simple entity component system which supports all of the previously-discussed storage strategies, then I will carry out some benchmarks and discuss the results.
You can skip to the benchmarks if you're just here to look at pretty graphs.
Otherwise, read on!
The public interface
Our implementation will expose a very simple public interface. One of the goals was to keep the implementation thin, simple, and performant.
void init(EntityComponentSystem* ecs); void free(EntityComponentSystem* ecs);
init() and free() are obvious. One memsets the structure to 0. The other frees all members of the structure.
void begin(EntityComponentSystem* ecs);
begin() should be called before the system is used, but after all components and entities have been added. In practice all it does is set the ready flag - but it serves as a useful synchronisation point for users to know when the system has been set up.
void update(EntityComponentSystem* ecs, float dt);
The user will call the update() function once per sim frame. This will process the entity creation and deletion queue, then it will tick each system. More on this later.
Component register_component(EntityComponentSystem* ecs,
const char* name,
size_t data_size,
uint8_t alignment,
ComponentAllocationStrategy::Enum allocation = ComponentAllocationStrategy::block);
register_component() creates a description of a component and returns the index to that component. All components must be registered before they can be used. The return value is a handle identifying that component. The most interesting thing here is the ComponentAllocationStrategy enum. Components can choose a default storage state.
System register_system(EntityComponentSystem* ecs,
const char* name,
uint8_t stream_count,
StreamLayout* streams,
SystemCbSystemUpdate system_update,
void* user_data = nullptr);
register_system() is the system-equivalent to register_component(). Of interest here is the StreamLayout*, which will be discussed in more detail soon.
Entity entity_create(EntityComponentSystem* ecs, size_t component_count, const Component* components,
EntityComponentDataInit init = nullptr, void* user_data = nullptr);
entity_create() will create an entity and return its ID. The creation doesn't happen until the next time update() is called, so an optional initialisation function and user_data combination may be provided so users can initialise the entities' components once it has been created if custom initialisation logic is required.
void* entity_get_component(EntityComponentSystem* ecs, Entity entity, Component component); void entity_get_all_components(EntityComponentSystem* ecs, Entity entity, void** out_components);
entity_get_component() and entity_get_all_components() do exactly what you would expect. These functions are slow and should be called sparingly. An alternative is provided in the form of the stream system, which we will discuss shortly.
inline uint32_t read_stream_entry(void* stream, uint32_t entry, ecs::Entity* entity, uint8_t component_count, void** components); inline uint32_t stream_start(void* stream, ecs::Entity* entity,uint8_t component_count, void** component);
These functions represent the stream API used exclusively inside the System update functions to query components. You'll understand them soon, I promise!
Creating the ECS
We have a simple system. Each entity in our game world represents a sprite on the screen. First of all, let's set up our ECS:
ecs::EntityComponentSystem our_ecs; ecs::init(&our_ecs);
Now that we have our ECS, we need to create our components. We will model this as three separate components:
struct Dirty
{
uint8_t dirty;
};
struct Transform
{
float x;
float y;
float rotation;
float scale;
};
struct Render
{
void* sprite;
};
The Transform and Render component have a fairly obvious function. The Dirty component is less obvious - it represents whether or not that entity's transform is dirty (and therefore needs to be uploaded to the transform UBO).
We create our components like this:
ecs::Component dirty_component = ecs::register_component(&ecs, "dirty", sizeof(Dirty), alignof(Dirty)); ecs::Component transform_component = ecs::register_component(&ecs, "transform", sizeof(Transform), alignof(Transform)); ecs::Component render_component = ecs::register_component(&ecs, "render", sizeof(Render), alignof(Render));
Finally, we need a system to process these components. Our system will handle updating the transform UBO of all dirty transforms, then it will render each sprite.
ecs::System render_system = ecs::register_system(&our_ecs, "render", stream_count, stream_layout, &system_update);
Note the stream_count, stream_layout, and &system_update. I pulled those variables out of my ass, but don't worry - I'll explain what they mean very soon.
Now that we've set up our components and systems, we need to let the ECS know we're ready to create entities:
ecs::begin(&our_ecs);
We're free to add entities now. Let's add a million, give or take a few bits, initialised with random positions and scales and using a random texture:
void init_entity(ecs::EntityComponentSystem* ecs, void*, size_t, void** component_data)
{
Dirty* dirty_component = (Dirty*)component_data[0];
Transform* transform_component = (Transform*)component_data[1];
Render* render_component = (Render*)component_data[2];
dirty_component->dirty = 1;
transform_component->x = random_in_screen_width();
transform_component->y = random_in_screen_height();
transform_component->rotation = random_rotation();
transform_component->scale = random_scale();
render_component->sprite = select_random_sprite();
};
...
ecs::Component components[3] = { dirty_component, transform_component, render_component };
for (size_t i = 0; i < 1024 * 1024; ++i)
{
ecs::entity_create(&our_ecs, 3, components, &init_entity);
}
We've created our entities. Remember that their components haven't been created yet - that only happens when update is next called. Which leads us to our main loop ...
while (true)
{
ecs::update(&our_ecs, last_frame_dt);
}
With that, our ECS is alive!
Understanding the stream model
Each frame, system_update() (which is our render system's update function) will be called with a cache-friendly pre-computed list of entities that it cares about provided by the ECS in the format that the system requested. These are streams. Systems are associated with one or more streams. A stream describes the component access patterns that the system wishes to use. They are only updated when something about the memory layout changes, so there is minimal overhead, and no time spent looking up components during the system update.
When creating a system, the user provides stream_count number of stream_layouts.
struct StreamLayoutComponent
{
enum AccessFlags : uint8_t
{
read = 1 << 0,
write = 1 << 1
};
ecs::Component component;
uint8_t access;
};
struct StreamLayout
{
bool include_entity_id;
uint8_t component_count;
StreamLayoutComponent* components;
};
Let's think about our render system. We have three components. We're going to read and write to one component (the dirty component), and read from the other two components. A simple stream layout, which we'll later tweak, would look like this:
ecs::Component components[3] = { dirty_component, transform_component, render_component };
...
ecs::StreamLayoutComponent layout_components[3];
layout_components[0].access = ecs::StreamLayoutComponent::read | ecs::StreamLayoutComponent::write;
layout_components[0].component = components[0];
layout_components[1].access = ecs::StreamLayoutComponent::read;
layout_components[1].component = components[1];
layout_components[2].access = ecs::StreamLayoutComponent::read;
layout_components[2].component = components[2];
ecs::StreamLayout layout;
layout.include_entity_id = true;
layout.component_count = 3;
layout.components = layout_components;
You might be wondering what the purpose of the access flags is for each component. This is useful for scheduling system concurrency. We won't be covering that in this article, but keep it in mind - knowing what we do to each component is useful when it comes to optimizing our job graph.
The stream layout specified above will give us this format of data in a flat array provided in the update function of our system:

To read data from a stream, we must use the stream data access API described earlier. An example of a simple system update loop is shown below:
void system_update(ecs::EntityComponentSystem*, void*, float, uint8_t, void** streams, uint32_t* stream_lens)
{
void* stream = streams[0];
uint32_t stream_len = stream_lens[0];
ecs::Entity entity;
void* components[3];
for (uint32_t i = ecs::stream_start(stream, &entity, 3, components);
i < stream_len;
i = ecs::read_stream_entry(stream, i, &entity, 3, components))
{
Dirty* dirty_component = (Dirty*)components[0];
if (dirty_component->dirty)
{
dirty_component->dirty = 0;
update_ubo_for_entity(entity, (Transform*)components[1]);
}
render_entity((Render*)components[2]);
}
}
Given that each component, by default, is stored using the block storage type, and we didn't specify a storage type during our component creation, our access pattern would look like this:

We access three different memory blocks, one per component - probably not a big deal. Since we're iterating over each block from start to finish, the prefetcher is going to have a good time here.
Component storage strategies
In this ECS, we have four storage strategies, which I explained in detail the last article - I'll quickly provide a summary here. Note that all storage strategies except for heap are stored in fixed-size sections of 32kb.
namespace ComponentAllocationStrategy
{
enum Enum : uint8_t
{
group_interleaved,
group_noninterleaved,
block,
heap,
};
}
Component storage: group_interleaved
All components in the same group are packed together in one single flat array. Otherwise known as AoS.

Component storage: group_noninterleaved
All components in the same group are stored in the same array, but packed together with the same type of component. Otherwise known as SoA.

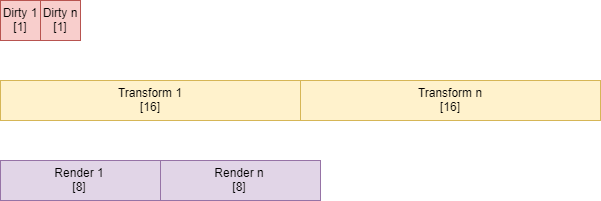
Component storage: block
Each component is packed in a flat block with other components of its type.
Component storage: heap
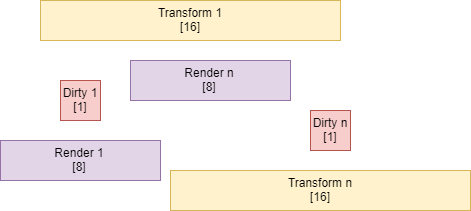
Each component is individually heap allocated.
Entity archetypes
Both of the grouped storage methods must choose exactly where they wish to group their components in memory. This is done by assigning each entity an archetype on creation. There is one archetype per combination of grouped components. This ensures that all entities with the same layout of grouped components (and in the same order) have those components packed together in memory.
A good change here, which I simply haven't had time to make yet, is to allow users to specify their own archetype too - and make the end archetype: internal_archetype | (user_archetype << 16). Users would be able to intelligently group components on a per-entity basis this way, rather than only on a per-component way as it stands now.
Benchmarking the component storage strategies
Each test is run 16 times every time an additional 5000 entities are added to the simulation and the average update time is captured, which means the cache is warm for all of these tests. In the real world, many more systems would operate on far fewer entities, all with a cold cache, which I suspect would further benefit the data-oriented storage strategies.
Before I reveal the results, I want to highlight that this is a micro-benchmark. All we are measuring here is the cache overhead caused by the different component storage strategies. In a real-world application, this is only a small part of the overall story - so please keep that in mind.
Finally, these tests were run on one core, single-threaded.
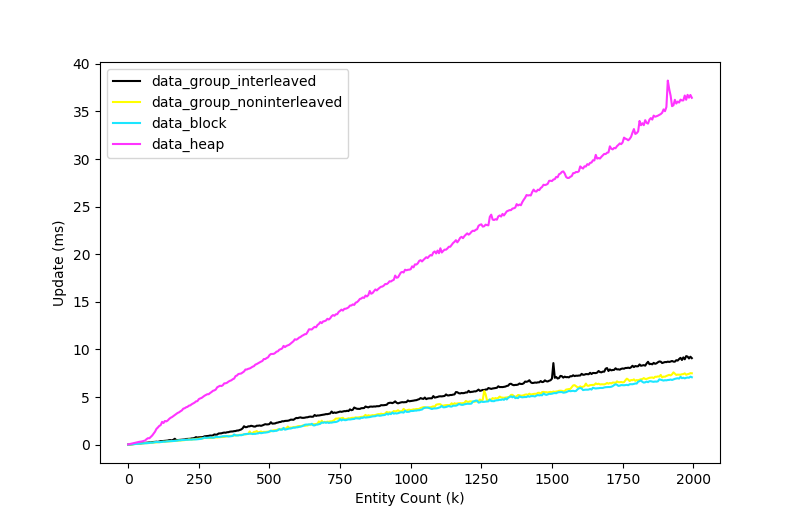
As we can see, the performance delta between the heap storage and the other three storage types is massive. This was expected. What I didn't expect to see here was that interleaved components performed marginally slower than non-interleaved components. In this test, I expected interleaved to win. Perhaps the result would be different in a more realistic scenario where temporal locality failed us and we were thrashing the cache so much we couldn't fit three separate lines into the cache at the same time.
This does leave me wondering whether we might see even better performance by storing the stream data in non-interleaved format rather than the current interleaved format. But that would occupy even more cache lines. Maybe not an issue on systems with a big L1 cache. Food for thought!
Not pictured here are the performance results when we do the same thing but without the ECS abstraction, iterating one big flat array per component type - coming in at about 1.8ms for 2000k entities which is approximately 3x faster than any of our results! When we create an Entity class and store the component offset on that instead, the time jumps up to match our ECS times. This demonstrates how expensive it is to index into an array based on an offset which is dependent on a memory load. Vectorisation might play into it too. I haven't had a chance to inspect the assembly yet, but I'll update this spot when I do.
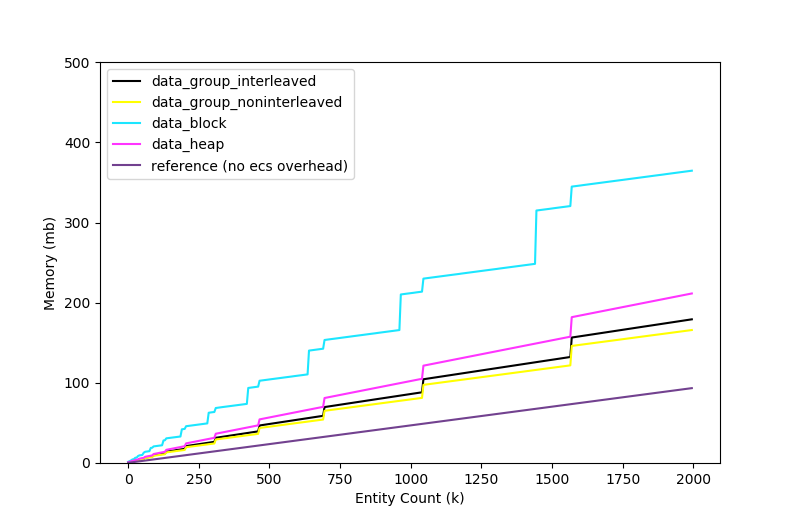
The memory reveals the implementation details of our storage - specifically, when the entity metadata array is resized, and more specifically to block storage when the hashmap mapping between entity and index grows, or for heap-allocated components, when the component lookup table is created.
It also shows that there is a significant overhead associated with our ECS implementation. It costs us about 75% memory overhead to store our components in the ECS and access them via systems compared to allocating the components naively and storing the pointers on some entity.
This is, in large part, due to the metadata we store per entity and per stream - each stream takes up 8 bytes per component per entity plus 8 bytes if the entity ID is inlined into the stream (4 for the ID, 4 for alignment padding). There is additionally 24 bytes used per entity to track metadata (section/data offsets for interleaved, noninterleaved, and a pointer to a table of heap allocated components which is created if any components are heap allocated).
In total, that's 46mb overhead for the entity metadata and 61mb overhead for the cached stream size at 2 million entities. There is a small amount of additional overhead to track each fixed-size section - 40 bytes plus padding for every 32kb section.
As always, it comes down to a trade-off between memory and performance. We could eliminate streams entirely and save 61mb but each system would need to perform a component lookup for each entity. We could save 15mb by removing support for heap allocated components entirely, and another 15mb if we removed support for interleaved components.
Multiple streams
In our previous example, we only used one stream. Are there any benefits to using two streams?
ecs::Component dirty_component = ecs::register_component(&ecs, "dirty", sizeof(Dirty), alignof(Dirty),
ecs::ComponentAllocationStrategy::group_noninterleaved);
ecs::Component transform_component = ecs::register_component(&ecs, "transform", sizeof(Transform), alignof(Transform),
ecs::ComponentAllocationStrategy::group_noninterleaved);
ecs::Component render_component = ecs::register_component(&ecs, "render", sizeof(Render), alignof(Render),
ecs::ComponentAllocationStrategy::block);
ecs::Component components[3] = { dirty_component, transform_component, render_component };
ecs::StreamLayoutComponent s0_layout_components[3];
s0_layout_components[0].access = ecs::StreamLayoutComponent::read | ecs::StreamLayoutComponent::write;
s0_layout_components[0].component = components[0];
s0_layout_components[1].access = ecs::StreamLayoutComponent::read;
s0_layout_components[1].component = components[1];
ecs::StreamLayoutComponent s1_layout_component;
s1_layout_component.access = ecs::StreamLayoutComponent::read;
s1_layout_component.component = components[2];
ecs::StreamLayout layouts[2] =
{
{ true, 2, s0_layout_components },
{ false, 1, &s1_layout_component }
};
...
void system_update(ecs::EntityComponentSystem*, void*, float, uint8_t, void** streams, uint32_t* stream_lens)
{
{ // dirty/transform stream
void* transform_stream = streams[0];
uint32_t transform_stream_len = stream_lens[0];
ecs::Entity entity;
void* components[2];
for (uint32_t i = ecs::stream_start(transform_stream, &entity, 2, components);
i < transform_stream_len;
i = ecs::read_stream_entry(transform_stream, i, &entity, 2, components))
{
Dirty* dirty_component = (Dirty*)components[0];
if (dirty_component->dirty)
{
dirty_component->dirty = 0;
update_ubo_for_entity(entity, (Transform*)components[1]);
}
}
}
{ // render stream
void* render_stream = streams[1];
uint32_t render_stream_len = stream_lens[1];
void* render_component;
for (uint32_t i = ecs::stream_start(render_stream, nullptr, 1, &render_component);
i < render_stream_len;
i = ecs::read_stream_entry(render_stream, i, nullptr, 1, &render_component))
{
render_entity((Render*)render_component);
}
}
}
Let's have a look at the performance.
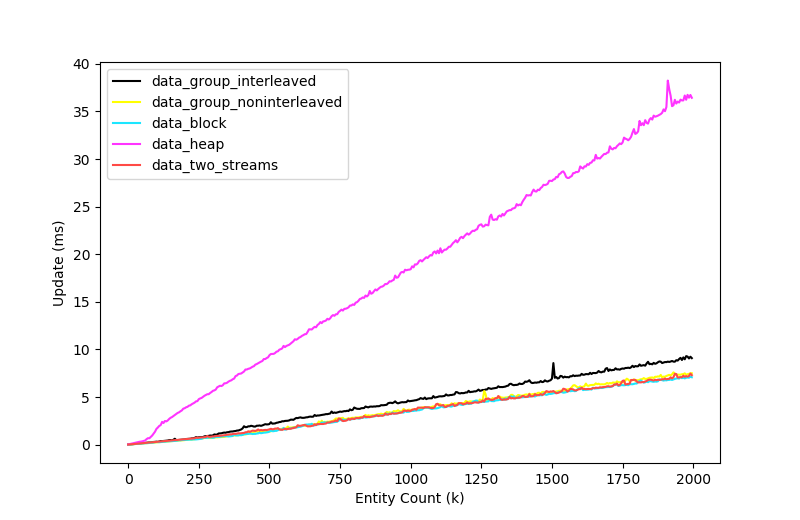
The answer, in this case, is no. Using two streams costs a small amount of memory overhead and provides no performance benefit. I suspect in a more complex system, where there was more cache contention and components allocations were fragmented, this approach would see some wins simply because each stream is sorted based on the first component's address in the stream, so by separating the two streams this way, we can obtain better cache performance. But, in this benchmark, there's no improvement.
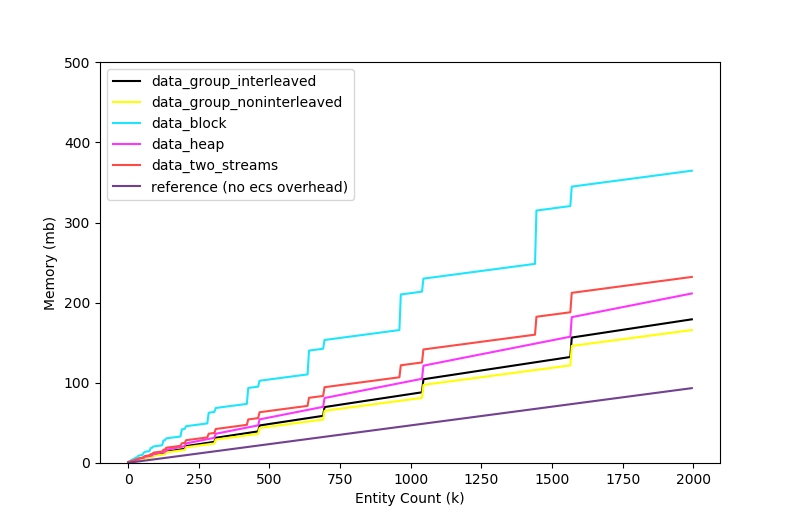
There's nothing special about the two stream memory usage compared to the single stream. There is a slight increase in memory usage because one of our three components is now using the block storage strategy.
Can we fix heap allocations?
In the last article, I mentioned that heap allocations using a custom allocator could perform better than random heap allocations. These are the results of running the benchmark using a small block allocator, which groups together small components in a mostly ascending linear order through memory.
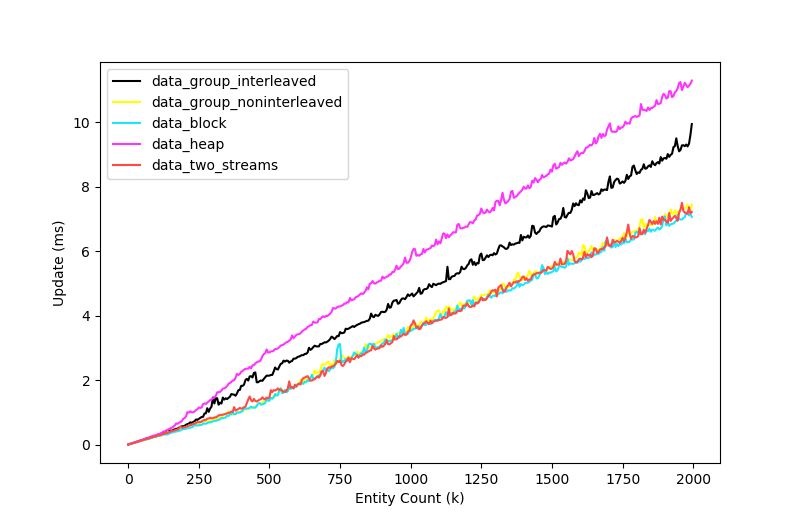
As you can see, the difference between naive heap allocations and data-oriented storage is still significant, but it's not as crazy as it was before. In a more complex game with other allocations fragmenting the small block allocator, I suspect this delta would grow.
Conclusions
The most appropriate default component storage type appears to be component block storage allocated in fixed-size sections. This ensures spatial locality while avoiding expensive array reallocation costs. There is a large memory overhead associated with this storage type as it is necessary to keep a hash map with a bucket count of total_entity_count at least.
For systems or components that have very specific storage requirements, or if operating in a cache- or memory- constrained environment, using one of the grouped storage methods may be best for you. These methods ensure greater spatial locality when iterating over a set of components in a system when compared to block storage with a lower memory overhead cost.
Heap-allocated components should be avoided. Even if you use a custom allocator, there is still a significant performance cost to ignoring the spatial locality of your components.
Reference benchmark code
For reference, here is the benchmarking code in its entirety.
namespace ecs_bench
{
struct Dirty
{
uint8_t dirty;
};
struct Transform
{
float x;
float y;
float rotation;
float scale;
};
struct Render
{
void* sprite;
};
void update_ubo_for_entity(ecs::Entity entity, Transform* transform)
{
static volatile char data[4096];
for (int i = 0; i < 32; ++i)
{
int offset = i * 128;
*(data + offset);
data[i * offset + 0] = (char)entity;
data[i * offset + 1] = (char)transform->x;
data[i * offset + 2] = (char)transform->y;
data[i * offset + 3] = (char)transform->rotation;
data[i * offset + 4] = (char)transform->scale;
}
}
void render_entity(Render* render)
{
static volatile bool rendered;
rendered = (uintptr_t)render->sprite % 4;
}
void system_update_normal(ecs::EntityComponentSystem*, void*, float, uint8_t, void** streams, uint32_t* stream_lens)
{
ecs::Entity entity;
void* components[3];
for (uint32_t i = ecs::stream_start(streams[0], &entity, 3, components);
i < stream_lens[0];
i = ecs::read_stream_entry(streams[0], i, &entity, 3, components))
{
Dirty* dirty_component = (Dirty*)components[0];
if (dirty_component->dirty)
{
dirty_component->dirty = 0;
update_ubo_for_entity(entity, (Transform*)components[1]);
}
render_entity((Render*)components[2]);
}
}
void system_update_fast(ecs::EntityComponentSystem*, void*, float, uint8_t, void** streams, uint32_t* stream_lens)
{
{ // dirty/transform stream
ecs::Entity entity;
void* components[2];
for (uint32_t i = ecs::stream_start(streams[0], &entity, 2, components);
i < stream_lens[0];
i = ecs::read_stream_entry(streams[0], i, &entity, 2, components))
{
Dirty* dirty_component = (Dirty*)components[0];
if (dirty_component->dirty)
{
dirty_component->dirty = 0;
update_ubo_for_entity(entity, (Transform*)components[1]);
}
}
}
{ // render stream
void* render_component;
for (uint32_t i = ecs::stream_start(streams[1], nullptr, 1, &render_component);
i < stream_lens[1];
i = ecs::read_stream_entry(streams[1], i, nullptr, 1, &render_component))
{
render_entity((Render*)render_component);
}
}
}
void do_bench(ecs::EntityComponentSystem* ecs, const char* name)
{
double min = FLT_MAX;
double max = -FLT_MAX;
double mean = 0.0;
double mean_total = 0.0;
static constexpr size_t runs = 16;
for (size_t i = 0; i < runs; ++i)
{
uint64_t time_before = utility::get_time_in_ns();
ecs::update(ecs, 1.0f);
uint64_t time_after = utility::get_time_in_ns();
double as_seconds = (time_after - time_before) * 1e-9;
if (as_seconds < min) min = as_seconds;
if (as_seconds > max) max = as_seconds;
mean_total += as_seconds;
}
mean = mean_total / runs;
float memory_usage_in_mb = memory::get_allocated_bytes(memory::tag::user_ecs) / 1024.0f / 1024.0f;
printf("{ \"%s\", %f, %f, %f, %f, %f },\n", name, min, max, mean, mean_total, memory_usage_in_mb);
}
static constexpr size_t base_entity_count = 5000;
static constexpr size_t steps_max = 400;
void do_generic(ecs::ComponentAllocationStrategy::Enum type, const char* name)
{
ecs::EntityComponentSystem ecs;
ecs::init(&ecs);
ecs::Component dirty_component = ecs::register_component(&ecs, "dirty", sizeof(Dirty), alignof(Dirty), type);
ecs::Component transform_component = ecs::register_component(&ecs, "transform", sizeof(Transform), alignof(Transform), type);
ecs::Component render_component = ecs::register_component(&ecs, "render", sizeof(Render), alignof(Render), type);
ecs::Component components[3] = { dirty_component, transform_component, render_component };
ecs::StreamLayoutComponent layout_components[3];
layout_components[0].access = ecs::StreamLayoutComponent::read | ecs::StreamLayoutComponent::write;
layout_components[0].component = components[0];
layout_components[1].access = ecs::StreamLayoutComponent::read;
layout_components[1].component = components[1];
layout_components[2].access = ecs::StreamLayoutComponent::read;
layout_components[2].component = components[2];
ecs::StreamLayout layout;
layout.include_entity_id = true;
layout.component_count = 3;
layout.components = layout_components;
ecs::register_system(&ecs, "render", 1, &layout, &system_update_normal);
ecs::begin(&ecs);
size_t entity_count = 0;
size_t next_entity_count = base_entity_count;
for (size_t steps = 0; steps < steps_max; ++steps)
{
for (size_t i = 0; i < next_entity_count - entity_count; ++i)
{
ecs::entity_create(&ecs, 3, components);
}
entity_count = next_entity_count;
next_entity_count = entity_count + base_entity_count;
ecs::update(&ecs, 0.0f);
char buff[128];
sprintf(buff, "%s %zu", name, entity_count);
do_bench(&ecs, buff);
}
ecs::free(&ecs);
}
void do_fast()
{
ecs::EntityComponentSystem ecs;
ecs::init(&ecs);
ecs::Component dirty_component = ecs::register_component(&ecs, "dirty", sizeof(Dirty), alignof(Dirty),
ecs::ComponentAllocationStrategy::group_noninterleaved);
ecs::Component transform_component = ecs::register_component(&ecs, "transform", sizeof(Transform), alignof(Transform),
ecs::ComponentAllocationStrategy::group_noninterleaved);
ecs::Component render_component = ecs::register_component(&ecs, "render", sizeof(Render), alignof(Render),
ecs::ComponentAllocationStrategy::block);
ecs::Component components[3] = { dirty_component, transform_component, render_component };
ecs::StreamLayoutComponent s0_layout_components[3];
s0_layout_components[0].access = ecs::StreamLayoutComponent::read | ecs::StreamLayoutComponent::write;
s0_layout_components[0].component = components[0];
s0_layout_components[1].access = ecs::StreamLayoutComponent::read;
s0_layout_components[1].component = components[1];
ecs::StreamLayoutComponent s1_layout_component;
s1_layout_component.access = ecs::StreamLayoutComponent::read;
s1_layout_component.component = components[2];
ecs::StreamLayout layouts[2] =
{
{ true, 2, s0_layout_components },
{ false, 1, &s1_layout_component }
};
ecs::register_system(&ecs, "render", 2, layouts, &system_update_fast);
ecs::begin(&ecs);
size_t entity_count = 0;
size_t next_entity_count = base_entity_count;
for (size_t steps = 0; steps < steps_max; ++steps)
{
for (size_t i = 0; i < next_entity_count - entity_count; ++i)
{
ecs::entity_create(&ecs, 3, components);
}
entity_count = next_entity_count;
next_entity_count = entity_count + base_entity_count;
ecs::update(&ecs, 0.0f);
char buff[128];
sprintf(buff, "fast %zu", entity_count);
do_bench(&ecs, buff);
}
ecs::free(&ecs);
}
}
TEST_CASE("ecs benchmark - generic", "[ecs]")
{
ecs_bench::do_generic(ecs::ComponentAllocationStrategy::group_interleaved, "group_interleaved");
ecs_bench::do_generic(ecs::ComponentAllocationStrategy::group_noninterleaved, "group_noninterleaved");
ecs_bench::do_generic(ecs::ComponentAllocationStrategy::block, "block");
ecs_bench::do_generic(ecs::ComponentAllocationStrategy::heap, "heap");
REQUIRE(memory::get_all_allocated_bytes() == 0);
}
TEST_CASE("ecs benchmark - fast", "[ecs]")
{
ecs_bench::do_fast();
REQUIRE(memory::get_all_allocated_bytes() == 0);
}
Next time, on Cerulean Skies
In this article I provided an overview of a cache-friendly entity component system and benchmarked the various storage strategies for components. In the next article of this series I will dive into the implementation details of the ECS, so you can write something similar if you want to!