Designing a cache-friendly entity component system
Preface: Consider all of the code in this article to be psuedocode. It is not guaranteed to compile as-is.
We're making a game. Our game must render many objects. Let's presume we want to implement this in terms of an object-oriented Entity Component System. How would we do this, naive C++-style? Probably something like this:
struct RenderComponent : public IComponent
{
IRenderResource* texture;
IRenderResource* shader;
};
struct TransformComponent : public IComponent
{
math::Position position;
math::Orientation orientation;
float scale;
};
class MyEntity : public IEntity
{
std::unique_ptr<RenderComponent> render_component;
std::unique_ptr<TransformComponent> transform_component;
};
class RenderSystem : public ISystem
{
void set_texture(IRenderComponent* texture) { ... }
void set_shader(IRenderComponent* shader) { ... }
void draw(TransformComponent* transform) { ... }
virtual void process(MyEntity* entity) override
{
set_texture(entity->render_component.get());
set_shader(entity->render_component.get());
draw(entity->transform_component.get());
}
};
The performance of this code will be terrible, unfortunately. There is too much indirection here. Each entity is allocated on the heap, as is each component, and individually per-entity. It's pointer chasing all the way down. Consider iterating an array of these entities:
for (MyEntity* entity : entities)
{
IRenderResource* texture = entity->render_component->texture;
math::Position position = entity->transform_component->position;
}
It might not seem too bad at first glance, but remember that each entity and each transform component are scattered around randomly in memory. We're triggering one memory load for the entity array, then one memory load for the entity, then one memory load for the render component. Add in the transform component and that's the fourth load. But the memory loads aren't the slow part here. They are irrelevant compared to the cache misses they cause. One cache miss is awful - and we're very likely to trigger three per entity each time around the loop, which is atrocious!

How can we improve this?
Mike Action-ing it
Let's replace the std::unique_ptrs with offsets into a flat-allocated array instead. Now we're thinking with a structure of arrays rather than an array of structures.
struct ComponentData
{
std::vector<RenderComponent> render_components;
std::vector<TransformComponent> transform_components;
};
class MyEntity : public IEntity
{
std::size_t render_component_index;
std::size_t transform_component_index;
};
How would we loop over this?
for (MyEntity* entity : entities)
{
IRenderResource* texture = data->render_components[entity->render_component_index].texture;
math::Position position = data->transform_components[entity->transform_component_index].position;
}
We're iterating through a contiguous chunk of memory as we access each component, which will result in fewer cache misses. One cache miss for the entities array, plus one cache miss for the ComponentData structure and one cache miss for each render component array as it is accessed. That's four cache misses in total, but only at the start of the loop. There will be one cache miss per loop iteration caused by the heap-allocated entity. Each entity won't incur an additional cache miss unless the component size exceeds the size of a cache line.
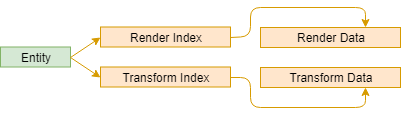
For systems that only consume one component, this setup represents the ideal memory layout. Rather than iterating over entities, the system could instead iterate over all data directly, like so:
for (const RenderComponent& render_component : data->render_components)
{
render(render_component);
}
This is a pretty good result. I'd be happy with this setup from a performance point of view. But is there anything else we can do to improve this?
What is an entity?
The next step is to rethink the concept of an Entity entirely. Using inheritance to represent entities means that every entity requires a heap allocation. We could store entities in a flat-allocated array per-entity-type like we're now doing with components, but this is messy and difficult to implement neatly with our current design. Instead, we could change what an Entity fundamentally is:
using Entity = std::uint64_t;
If we consider an entity to be nothing more than a key, then it is possible for us to avoid a cache miss for looking up the entity. This approach does bring with it a problem, however: we need to track the component indices in each of the flat-allocated arrays per-entity. A simple solution is to resize each component array to match the entity array then simply index into it using the entity ID. Though this provides fast lookup, it does carry a steep memory overhead and is not recommended.
A solution that is lighter on the memory overhead is to store an array of offsets, one element per possible component, into the component array in the ComponentData structure. If we assume that we can get away with an std::uint16_t for the offset per-component, we have only 2 bytes overhead per entity per possible component in the system. This may become problematic as your system grows.
Another solution is to store a map between entity ID and the offset, one map per possible component. std::unordered_map is not suitable here as its allocation strategy is poor. A simple implementation of a hash map which uses open addressing and stores the key and value together in a flat array is ideal. The code would look something like this:
struct ComponentData
{
my::open_address_hash_map<Entity, std::uint16_t> render_entity_to_offset_map;
std::vector<RenderComponen> render_components;
my::open_address_hash_map<Entity, std::uint16_t> transform_entity_to_offset_map;
std::vector<TransformComponen> transform_components;
}
And our loop would look like this:
for (Entity entity : entities)
{
IRenderResource* texture = data->render_components[data->render_entity_to_offset_map[entity]].texture;
math::Position position = data->transform_components[data->transform_entity_to_offset_map[entity]].position;
}
Compared to the earlier approach, we'd incur two more cache misses at the start of the loop (one per map), but we'd lose the cache miss per entity, providing us with a significant net win. Compared to the naive approach, we go from 1 cache miss upfront and 3 cache misses per entity, to 6 cache misses upfront and 0 cache misses per entity. It should be noted, however, that if your components are too large, or you access too many in the same loop, cache misses may still occur.
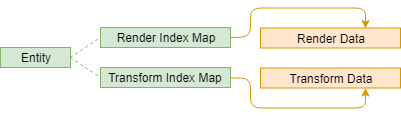
We've improved the memory layout a lot since we started. Is there anything else we can do?
Interleaving our data
We could consider storing components interleaved with each other.
struct RenderTransformEntityComponents
{
RenderComponent render_component;
TransformComponent transform_component;
};
struct ComponentData
{
my::open_address_hash_map<Entity, std::uint16_t> render_transform_entity_to_offset_map;
std::vector<RenderTransformEntityComponents> render_transform_components;
};
Depending on your use case, this could be better or worse than the earlier approach. If you're accessing many components at the same time then this solution will be better because there is less pointer chasing going on thanks to the locality of reference introduced here which will result in fewer cache misses. The loop would look the same as earlier, except with only one lookup.

Now that we're interleaving components, we should think about ways to eliminate the map lookup entirely.
Removing the map
Let's store an array of entity metadata. We will spend four bytes per entity. The first two bytes represent a section offset and the last two bytes represent a data offset.
struct EntityMetadata
{
std::uint16_t section_offset;
std::uint16_t data_offset;
};
We're also separating the definition of a component from its instance:
struct ComponentDefinition
{
const char* name;
size_t size;
uint8_t alignment;
};
using Component = std::uint64_t;
Additionally, we have an array of sections. Sections represent 'memory slices' of component data.
struct Section
{
std::vector<Component> components;
std::vector<std::byte> component_data;
};
When creating an entity, a list of components is provided:
Entity create_entity(std::vector<Component> components);
We iterate all of the sections currently created and compare the section's components array with our desired components. You may choose to ignore order of components here (sort first) or preserve it, depending on your memory layout objectives. If there's no exact match, we create a new section for our component combination. Once we have a section, we insert resize the component_data array + 1, then we set up our entity metadata.
EntityMetadata metadata; metadata.section_offset = find_or_create_section(components); metadata.data_offset = create_data(metadata.section_offset); entities.emplace_back(std::move(metadata));
The raw byte data is tricky to set up. We need to encode metadata into it. Broadly speaking, the byte stream should follow this format:
[5 bytes] component_id [1 bytes] component_alignment [2 bytes] component_length [alignment padding for component alignment] [component_length bytes] [alignment padding to ensure we're aligned to 8] ... [terminated when reaching components.size())
Accessing this data by hand is nasty. In a real scenario, we'd encapsulate this stuff in an ECS data structure. Even if we went in raw, a helper function would be handy:
template <typname T*>
T* get_component(Component component, const EntityMetadata& metadata)
{
Section* section = sections[metadata.section_offset];
for (int i = 0; i < section->components.size(); ++i)
{
std::byte head = section->component_data[metadata.data_offset];
// might be best to implement this with a struct and bitfields
std::uint64_t component_id = 0;
memcpy(&component_id, head, 5);
head += 5;
std::uint8_t component_alignment;
memcpy(&component_alignment, head, 1);
head += 1;
// don't read length unless we need to
head += 2;
if (component_id == component)
{
return (T*)(head + alignment(head, component_alignment));
}
std::uint16_t component_length;
memcpy(&component_length, head - 2, 2);
head += alignment(head, component_alignment);
head += component_length;
head += alignment_padding(head);
}
return nullptr;
}
Given that we now know the section offset and data offset per entity, we can skip the map completely and index directly using our helper function, like so:
for (EntityMetadata metadata : entity_metadata)
{
RenderComponent* render_component = get_component<RenderComponent>(RenderComponentId, metadata);
TransformComponent* transform_component = get_component<TransformComponent>(TransformComponentId, metadata);
}
This approach has one advantage over the last - it is no longer necessary to perform a map lookup, so we avoid the map memory overhead and lookup time. The lookup time is almost certainly quicker here compared to before. However, our cache performance does remain the same. This is because each section is allocated on the heap separately to the sections array.
This approach also gives us the choice we were faced with earlier - structure of arrays or array of structures. If you wanted, you could interleave a transform component with the render component, or you could interleave an x-, y-, and z- component in that order, all aligned to 16 for SIMD. How you lay out your data is entirely up to you. Interleaved sections just ensure that each entity's components are roughly together in memory, on the assumption that if you access one, you probably want to access more than one.

Can we make this better?
Fixed-size sections
Instead of growing each section as we use it, we can instead adopt fixed-size sections. For the sake of this example, I'm going with 32k-sized sections. Any size can work in practice. The bigger the section, the fewer cache misses you'll get per iteration (from jumping between sections), but the greater the wasted memory is.
struct Section
{
std::vector<Component> components;
std::uint16_t head;
// 6 bytes padding
std::vector<uint16_t> free_list;
// we're aligned to 8 here
std::byte component_data[32768];
};
You'll notice we've added a free_list and head. Because we can't grow the array dynamically, we track head - the highest index we've used. When we create an entity, we first check the free_list for its section. If the list is empty, we try head. If the head is greater than the size, we must create a new section instead.
The code to interface with the data looks the same, but we're spared one constant level of indirection, in exchange for memory overhead (which could be significant if you have many possible components with few actually used) and an additional cache miss every time iteration skips a chunk.
Another advantage of this approach, especially if we keep our section sizes low, is that we reduce times spikes from reallocating what could grow to be a very large interleaved array. Iteration time is not the only important consideration: entity creation and destruction time matters, too.

Surely that's everything we can do, right?
Taking it even further
A few approaches exist to further improve this solution.
Using template magic, it is possible to create a new function called get_components and return an std::tuple (or write to out arguments) each component address in one pass rather than taking multiple passes in get_component. If you don't like template magic, you could just use a stack-allocated array of pointers instead, and change the loop to store the pointers in the array.
Either way, this would turn O(log(N) * N) time into O(N) time when looking up all components on an entity. A huge improvement in a tight loop.
A custom allocator could be written which allocates separate sections of the same interleaved component setup next to each other in memory. This would avoid the occasional cache miss when iterating over all entities. You could reduce the section size to lower memory overhead.
Some of the handles (entity / component) that are defined as std::uint64_t may be able to drop to std::uint32_t, saving memory elsewhere.
[08/02/2018] Edited to add, in response to comments:Tune the ECS allocation strategy to your exact use case. Perhaps, for you, a mixture of interleaved and non-interleaved data is best, depending on the systems that will operate on that data. Consider two fixed-sized section blocks, rather than one - one which serves interleaved data and the other which serves non-interleaved data.
Systems that require access to non-interleaved data, like a bounding box stored in physics as 16-byte-aligned non-interleaved flat arrays of x, y, width, and height, will do the look-up in the non-interleaved section block, giving you good SIMD access patterns to [x x x x] [y y y y] [w w w w] [h h h h]. Systems that perform better with interleaving turned on - transform component and render component in the render loop - can still be interleaved in separate block.
Finally, consider the impact of memory fragmentation on your game. If you have large entity creation spikes where at the peak of the spike live a few long-lasting entities, this could result in poor cache performance. In this case, you may wish to consider incrementally defragmenting your sections.
Next time, on Cerulean Skies
All of the code here was written in C++. My ECS implementation is written in C. Well, it's C++-without-classes-or-std. In the next article of this series I'll share my implementation and describe how it is used in practice.